Introduction
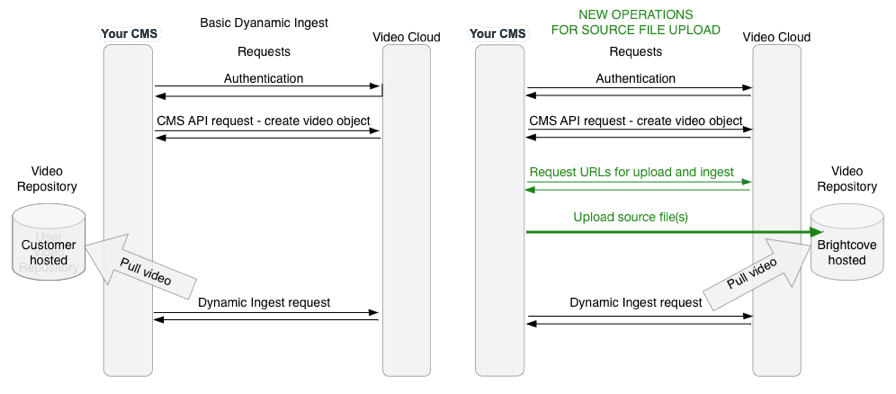
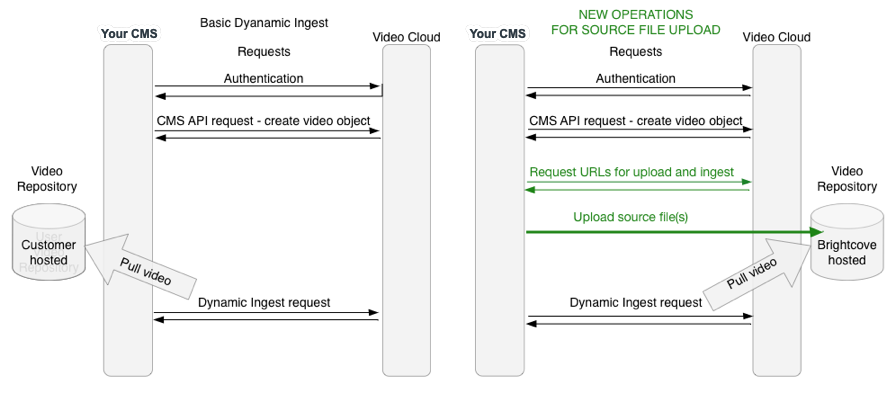
Pour l'ingestion via le téléchargement de fichier source, Brightcove fournit un compartiment S3 dans lequel vous pouvez télécharger vos vidéos et fichiers d'actifs, et Dynamic Ingest extrait ensuite la vidéo du compartiment S3 de la même manière qu'elle le ferait à partir de votre propre compartiment S3 ou URL. Le diagramme ci-dessous montre la différence entre les workflows pour l'ingestion dynamique de base et l'ingestion avec téléchargement de fichier source.
FAQ
- Combien de temps les vidéos sont-elles temporairement stockées et quand les URL correspondantes deviennent-elles invalides ?
- Les vidéos sont supprimées du stockage temporaire 24 heures après leur mise en ligne et leurs URL ne sont plus valides après cela.
- Combien de temps les informations d'identification S3 sont-elles renvoyées par le Dynamic Ingest API valide ?
- Les informations d'identification S3 sont également valides pendant 24 heures après leur envoi par l'API.
- Les fichiers vidéo sont-ils physiquement supprimés du compartiment S3 après 24 heures ?
- Oui
- Les vidéos sont-elles supprimées du compartiment S3 une fois qu'elles ont été ingérées avec succès ?
- Toutes les vidéos sont supprimées du stockage temporaire après 24 heures, qu'elles aient été ingérées avec succès ou non.
- Les vidéos stockées temporairement peuvent-elles être consultées publiquement par une personne possédant l'URL ?
- Non
- Existe-t-il un moyen de télécharger ou de visualiser la vidéo dans un stockage temporaire sans informations d'identification de sécurité ?
- Non
- Les informations d'identification de sécurité pour accéder au stockage temporaire sont-elles partagées avec d'autres clients Brightcove ?
- Non, tout client utilisant le stockage temporaire reçoit des informations d'identification de sécurité uniques.
- Existe-t-il un moyen pour d'autres clients Brightcove d'accéder à mes vidéos stockées temporairement en utilisant leurs propres informations d'identification de sécurité ?
- Non, les informations d'identification de sécurité ne donnent accès qu'aux vidéos que vous avez transférées vers un stockage temporaire.
- Dans quelle région réside le compartiment S3 pour les téléchargements de fichiers ?
- US-EAST-1 (ceci est corrigé).
Noms des fichiers sources
Pour éviter les problèmes d'accès aux vidéos et aux ressources dans Brightcove Player, vous devez éviter d'utiliser des caractères spéciaux dans les noms de fichiers source, qu'il s'agisse de vidéos, d'images ou de pistes de texte (fichiers WebVTT). Cela s'applique également aux actifs distants. Les noms de fichiers ne doivent inclure que les éléments suivants :
- Un seul octet lettres (majuscules ou minuscules)
- Nombres
- Tirets (-) et traits de soulignement (_)
- Les espaces s'ils sont codés en URL
Authentification
Le moyen le plus simple d'obtenir les informations d'identification du client pour l'ingestion dynamique consiste à la page d'administration de Studio pour l'authentification API. Pour les autorisations API, il vous faut au moins :
- CMS > Lecture vidéo
- Acquisition dynamique > Créer
- Ingest dynamique > Fichiers push (il s'agit de la nouvelle API de téléchargement de fichier source)
L'authentification pour les demandes d'API Brightcove pour l'ingestion push nécessite une autorisation supplémentaire par rapport à celles pour autres demandes d'ingestion dynamique:
video-cloud/upload-urls/read
L'ensemble complet des autorisations nécessaires pour le téléchargement du fichier source est :
- video-cloud/video/create
- vidéo-nuage/vidéo/lire
- vidéo-nuage/vidéo/mise à jour
- video-cloud/upload-urls/read
Ces autorisations sont disponibles dans Studio. Vous pouvez également obtenir les informations d'identification du client pour utiliser l'API de téléchargement de fichier source directement à partir de l'API OAuth en effectuant une requête POST comme suit :
URL de demande
https://oauth.brightcove.com/v4/client_credentials
Headers
Authorization: BC_TOKEN {YOUR_BC_TOKEN}-
Type de contenu : application/json
Corps de la demande
{
"type": "credential",
"maximum_scope": [
{
"identity": {
"type": "video-cloud-account",
"account-id": {YOUR_ACCOUNT_ID}
},
"operations": [
"video-cloud/upload-urls/read",
"video-cloud/video/create",
"video-cloud/video/read",
"video-cloud/video/update",
"video-cloud/ingest-profiles/profile/write",
"video-cloud/ingest-profiles/account/write",
"video-cloud/ingest-profiles/profile/read",
"video-cloud/ingest-profiles/account/read"
]
}
],
"name": "Source File Upload Credentials"
}Requêtes API
Il y a quatre requêtes API impliquées dans l'ingestion push :
- Requête CMS API POST pour créer l'objet vidéo dans Video Cloud (identique à l'ingestion basée sur l'extraction)
- Requête Dynamic Ingest GET pour obtenir les URL du compartiment Brightcove S3
- Demande PUT pour télécharger le fichier source dans le compartiment Brightcove S3
- Requête POST d'ingestion dynamique pour ingérer le fichier source (identique à l'ingestion basée sur l'extraction)
Ces demandes sont détaillées dans les sections qui suivent.
Demande d'API CMS
La CMS API demande est la même que pour toute opération Dynamic Inquest pour ajouter une nouvelle vidéo. Cette demande est nécessaire pour ingérer une nouvelle vidéo. Si vous remplacez ou ajoutez des éléments à une vidéo existante, vous n'aurez pas besoin de cette étape. À la place, vous utiliserez l'identifiant vidéo existant dans les autres demandes.
Syntaxe de la requête
C'est un POST demande à:
https://cms.api.brightcove.com/v1/accounts/{ACCOUNT_ID}/videos
Paramètres
Paramètres d'URL pour la requête :
{ACCOUNT_ID}- votre identifiant de compte
Corps de la demande
Le corps de la requête se compose d'un objet JSON contenant le name (obligatoire) et autres métadonnées pour la vidéo (facultatif) :
{
"name": "My Video"
}Voir le Référence API pour les détails.
Headers
Les en-têtes HTTP que vous devez inclure avec la requête sont :
Authorization: Bearer {ACCESS_TOKEN}Content-Type: application/json
Réponse
La réponse sera un objet JSON contenant les métadonnées de la vidéo. L'élément important pour le reste des opérations d'ingestion dynamique est le id , que vous substituerez au {VIDEO_ID} dans les requêtes à l'API Ingest.
Demande d'URL S3
La première demande à l'API Ingest récupérera les informations dont vous avez besoin pour METTRE vos fichiers sources dans le compartiment Brightcove S3, puis les ingérer à partir de là dans Video Cloud.
Syntaxe de la requête
C'est un GET demande à:
https://ingest.api.brightcove.com/v1/accounts/{ACCOUNT_ID}/videos/{VIDEO_ID}/upload-urls/{SOURCE_NAME}Paramètres
Paramètres d'URL pour la requête :
{ACCOUNT_ID}- votre identifiant de compte{VIDEO_ID}- l'identifiant vidéo retourné à partir de la CMS API requête{SOURCE_NAME}- le nom du fichier source vidéo - le nom ne doit pas contenir de caractères réservés à l'URL tels que?,&,#ou des espaces
Headers
Les en-têtes HTTP que vous devez inclure avec la requête sont :
Authorization: Bearer {ACCESS_TOKEN}
Réponse
La réponse sera un objet JSON semblable au suivant :
{
"bucket": "ingestion-upload-production",
"object_key": "57838016001/4752143002001/ed5a5ba0-1d97-4f95-a8ec-cbb786b04a37/greatblueheron.mp4",
"access_key_id": "ACCESS_KEY_APPEARS_HERE",
"secret_access_key": "SECRET_ACCESS_KEY_APPEARS_HERE",
"session_token": "FQoDYXdzEKf//////////wEaDKR0wDgquq/qvkZgbyKOA7URC/9io6cmRBDkhbvxoHIKkPZlK/9YNvdWcESPkm75/2PvU6FV1Mc+/XENPzY8KgvP86MBJNxYLPdkuP1phgHs2Yh2p1KIDcQSCZJ3i6i9m4S14ewjWIugYLYDQi6CG+3fiFwfzbKT5jes1kh24m9BQQIuvVOiM1GLTldyDzlrdDopJkdYd4IEU7FU36CUT7RL/aeMwR2Usk56nwqyqkkQHPmvqmGyiLdrD3OrIbUU+6+ZP4usS9dbV3eAqOWDIk3HCN+Kuc9f/eUWhY21ftNDXWgasqQqXwPRs3T1i/hoiIKODbzr8F",
"signed_url": "https://ingestion-upload-production.s3.amazonaws.com/57838016001/4752143002001/ed5a5ba0-1d97-4f95-a8ec-cbb786b04a37/greatblueheron.mp4?AWSAccessKeyId=ACCESS_KEY_HERE&Expires=1475673952&Signature=%2Fsr5cV%2FVOfGCBkodol9xQIKlbu4%3D",
"api_request_url": "https://ingestion-upload-production.s3.amazonaws.com/57838016001/4752143002001/ed5a5ba0-1d97-4f95-a8ec-cbb786b04a37/greatblueheron.mp4"
}Les éléments de la réponse sont :
bucket- le nom du compartiment S3object_key- la clé d'objet pour le téléchargement de fichier (utilisée dans la construction de l'URL de destination pour les téléchargements en plusieurs parties)access_key_id- la clé d'accès utilisée pour authentifier la demande de téléchargement (utilisée pour les téléchargements en plusieurs parties)secret_access_key- la clé d'accès secrète utilisée pour authentifier la demande de téléchargement (utilisée pour les téléchargements en plusieurs parties)session_token- un jeton AWS de courte durée qui offre la possibilité d'écrire dans l'objet ciblesigned_url- il s'agit d'une URL S3 abrégée dans laquelle vous pouvez METTRE votre (vos) fichier(s) source si vous avez des vidéos relativement petites et que vous n'implémentez pas le téléchargement en plusieurs partiesapi_request_url- il s'agit de l'URL que vous inclurez dans votre demande POST d'ingestion dynamique pour l'URL principale ou l'URL pour les actifs image/text_tracks
Il est recommandé d'utiliser le téléchargement partitionné à l'aide du kit AWS SDK pour la langue que vous utilisez. Les SDK sont disponibles pour de nombreux langages, notamment Java, .NET, Ruby, PHP, Python, JavaScript, Go et C++. Voir le Blog des développeurs AWS pour plus d'informations.
Si vous implémentez un téléchargement partitionné, les documents et exemples de code suivants vous seront utiles :
Voici un exemple simple en PHP :
<?php
//SDK AWS (pour les ingestion push)
requiert 'vendor/aws-autoloader.php' ;
utiliser Aws \ S3 \ S3Client ;
utiliser Aws \ S3 \ MultiPartuploader ;
utiliser Aws \ Exception \ MultiPartuploadException ;
/**
* obtenir les informations S3 comme décrit ci-dessus dans ce document
* le code ci-dessous suppose qu'il a été décodé comme $s3response
* et que $FilePath est le chemin d'accès local au fichier d'actifs
*/
s3 = nouveau S3Client ([
'version' = > 'dernière',
'region' = > 'us-est-1',
'Credentials' = > tableau (
'key' = > $s3response- > access_key_id,
'secret' = > $s3response- > secret_access_key,
'token' = > $s3response- > session_token
)
]) ;
$params = tableau (
'bucket' = > $s3response- > s3- > compartiment,
'key' = > $s3response- > s3- > object_key
) ;
$uploader = nouveau MultiPartuploader ($this- > s3, $filePath, $params) ;
essayez {
$uploadResponse = $uploader- > upload () ;
} catch (MultiPartuploadException $e) {
echo $e- > getMessage (). « \ n » ;
}
?>METTRE le(s) fichier(s) source(s) dans S3
Après avoir obtenu les URL S3, vous faites une demande PUT pour télécharger votre fichier vidéo, en utilisant le signed_url comme destination.
Vous pouvez utiliser ce qui suit boucle commande pour tester l'opération PUT :
curl -X PUT "SIGNED_URL_GOES_HERE" --upload-file FILE_PATH_FOR_LOCAL_ASSET_GOES_HERE
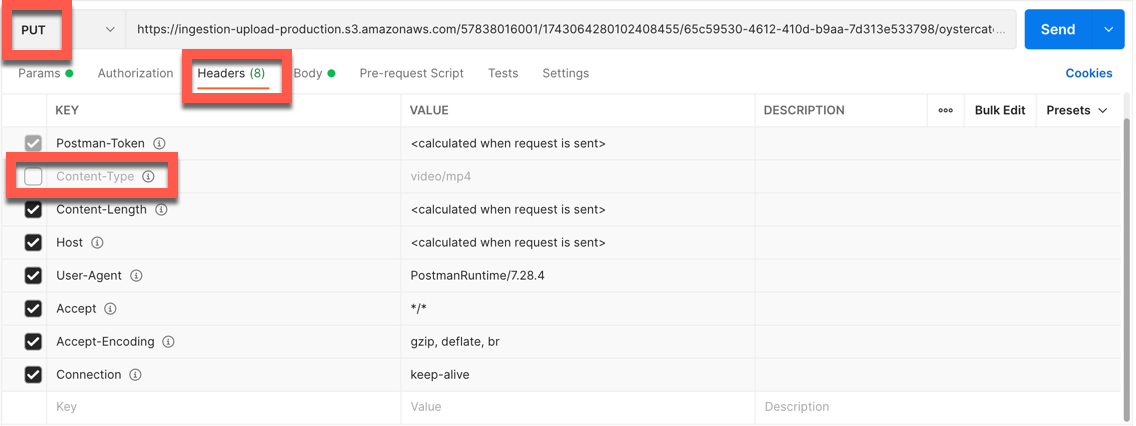
Si vous utilisez Postman pour envoyer le fichier à S3, vous devrez décocher l'en-tête Content-Type:
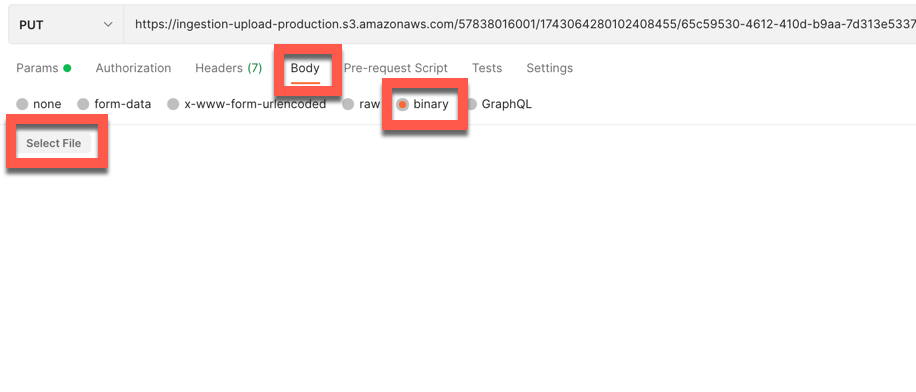
Veillez également à changer le type de corps en Binary et à sélectionner votre fichier vidéo à télécharger :
Téléchargement unique ou en plusieurs parties
AWS autorise les téléchargements en une seule partie pour les fichiers jusqu'à 5 Go (il n'y a pas d'autres limites sur la taille des fichiers). Pour les fichiers plus volumineux, vous devez utiliser des téléchargements en plusieurs parties. Bien que le téléchargement en une seule partie soit un peu plus facile à configurer, nous vous recommandons d'utiliser le téléchargement en plusieurs parties dans la mesure du possible. Voici les différences entre les deux :
- Le téléchargement en une seule partie télécharge la vidéo en un seul fichier. Le téléchargement en une seule partie est limité à des tailles de fichier de 5 Go ou moins. Si le téléchargement est interrompu pour une raison quelconque, vous devez recommencer.
- Le téléchargement en plusieurs parties envoie le fichier en morceaux. C'est plus efficace car le téléchargement peut tirer parti de plusieurs connexions. De plus, si le téléchargement est interrompu, il peut reprendre là où il s'était arrêté avec les morceaux restants.
Demande d'ingestion dynamique
Une fois que votre fichier a été chargé dans le compartiment Brightcove S3, vous effectuez une demande d'ingestion dynamique ordinaire pour ingérer le fichier à partir de son emplacement S3.
Syntaxe de la requête
C'est un POST demande à:
https://ingest.api.brightcove.com/v1/accounts/{ACCOUNT_ID}/videos/{VIDEO_ID}/ingest-requests
Paramètres
Paramètres d'URL pour la requête :
{ACCOUNT_ID}- votre identifiant de compte{VIDEO_ID}- l'identifiant vidéo retourné à partir de la CMS API requête
Corps de la demande
Le corps de la requête se compose d'un objet JSON contenant le master (obligatoires) détails pour la tâche d'ingestion. Les url pour le master sera le api_request_url renvoyé par la demande d'informations sur le compartiment S3
{
"master": {
"url": "https://ingestion-upload-prod.s3.amazonaws.com/12345/5678/3712cd37504911ab06a77a26a387ce/source.mp4"
},
"profile": "multi-platform-standard-static",
"capture-images": true
}
Voir le Référence API pour les détails.
Headers
Les en-têtes HTTP que vous devez inclure avec la requête sont :
Authorization: Bearer {ACCESS_TOKEN}Content-Type: application/json
Réponse
La réponse contiendra le job_id pour la demande d'ingestion, ce qui vous permet de suivre l'état via Notifications.
Exemple de code
Pour vous aider à démarrer avec l'ingestion dynamique basée sur push, nous avons créé des exemples d'applications en Java et Python. Vous pouvez les retrouver sur notre Site Github.